

Last Updated on January 24, 2024 by cscontents
Introduction
Kubernetes is the leading open-source container orchestration tool in today’s market (as of 16th Feb 2023) that is used to automate deployment, scaling, management, etc.
Speaking about the working of Kubernetes, fundamentally it is an API-driven system. Kubernetes uses API to manage containerized workloads. This API-driven approach allows us to define/deploy/manage deployable components as Kubernetes objects.
In this article, we will discuss Kubernetes objects and their manifest files.
Kubernetes objects Definition
Kubernetes objects are persistent entities in the Kubernetes system and these entities are used by Kubernetes to represent the state of the cluster. In other words, we can say these objects are the basic building blocks of the Kubernetes cluster.
If you are new to Kubernetes then you can have a look at the below article to get some idea.
Kubernetes Series: Part 1 – Introduction to Kubernetes | Background of Kubernetes
How can we create Kubernetes objects?
We can create any Kubernetes object using the kubectl command line tool. kubectl is an API client and it interacts with the Kubernetes API server.
Not only object creation, but we can also update, and delete any object using the kubectl command line tool.
Where do Kubernetes objects get stored?
When we create any Kubernetes object, it gets stored in the Kubernetes API server Through Kubernetes API only we can get details about this object & if required we can update/modify or delete the object.
Basic Structure of Kubernetes Objects (YAML)
We can create a Kubernetes object by mentioning the detailed configuration of that object in a YAML file. This YAML file is called an object manifest file. This manifest file specifies the desired state of the object. It is the job of the Kubernetes controller manager to ensure that the current state of the object matches the desired state which is mentioned in the manifest file (YAML file).
Now, by structure of the object, we mean the basic format or structure of the configuration file or object manifest file (YAML).
apiVersion: # mention API version kind: # kind of object, e.g., pod, service, etc. metadata: # put the required metadata spec: # put the specification of the object
All the Kubernetes object maintains this basic structure in their manifest file (YAML). So, once we understand this structure it would be very easy for us to deal with various Kubernetes objects.
If you want to learn Kubernetes object’s apiVersion in detail, then please head over to the below document.
https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.24/
Types of Kubernetes Objects
There are many Kubernetes objects. But in this article, we will see the commonly used objects.
- Namespace
- Pod
- Replication Controller
- Replicaset
- Deployment
- Daemonset
- Service
- NodePort
- ClusterIP
- LoadBalancer
- ConfigMap
- StatefulSet
- HorizontalPodAutoscaler
- VerticalPodAutoscaler
- StorageClass
- PersistentVolume
- PersistentVolumeClaim
- Job
Now we will see some basic details about these objects.
Namespace
Kubernetes namespace provides a way to isolate various resources in the Kubernetes cluster.
apiVersion: v1 kind: Namespace metadata: name: my-namespace labels: name: test
Pod
Pods are the smallest deployment unit in the Kubernetes cluster. Inside the pod, our application container runs. In a pod, one or multiple containers can run.
apiVersion: v1 kind: Pod metadata: name: my-sample-pod labels: app: my-sample-app spec: containers: - name: my-sample-container image: my-sample-app:v1 ports: - containerPort: 80
Replication Controller
Replication Controller is a Kubernetes object that ensures that the desired number of pods is always running.
apiVersion: v1 kind: ReplicationController metadata: name: my-sample-app-rc spec: replicas: 5 selector: app: my-sample-app template: metadata: labels: app: my-sample-app spec: containers: - name: my-sample-app-container image: my-sample-app:v1 ports: - containerPort: 80
ReplicaSet
ReplicaSet is like the Replication Controller. It is an updated version of the Replication Controller. Like a Replication Controller, it ensures that the desired number of pods is always running.
The main difference between ReplicaSet & Replication Controller is –
ReplicaSet uses set-based selectors whereas Replication Controller uses equality-based selectors.
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: my-sample-app-rs
spec:
replicas: 5
selector:
matchLabels:
app: my-sample-app
template:
metadata:
labels:
app: my-sample-app
spec:
containers:
- name: my-sample-app-container
image: my-sample-app:v1
ports:
- containerPort: 80
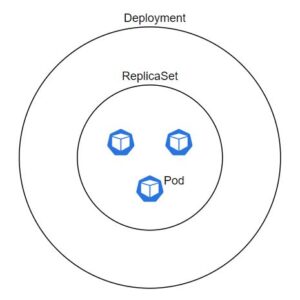
Deployment
Deployment is a Kubernetes object which is used to manage a set of pods. By managing I mean deploying a set of pods, upgrading them, deleting them, etc.
When we create a deployment object, it creates a ReplicaSet and ReplicaSet consists of a certain number of pods.
apiVersion: apps/v1 kind: Deployment metadata: name: my-sample-app-deployment spec: replicas: 5 selector: matchLabels: app: my-sample-app template: metadata: labels: app: my-sample-app spec: containers: - name: my-sample-app-container image: my-sample-app:v1 ports: - containerPort: 80 strategy: type: RollingUpdate rollingUpdate: maxUnavailable: 1 maxSurge: 1
Daemonset
Daemonset is a Kubernetes object that ensures a specific pod runs on every single node (computer) of your Kubernetes cluster.
apiVersion: apps/v1 kind: DaemonSet metadata: name: <name of the daemonset> namespace: <namespace> # It is Optional spec: selector: matchLabels: <key>: <value> # Labels to identify pods that will be managed by the DaemonSet. template: metadata: labels: <key>: <value> # Labels to apply to the target pods. spec: containers: - name: <name of the container> image: <image used in the container> # Container-specific other configuration is added here volumes: - name: <volume-name> <volume-type>: # Volume-specific configuration is added here
Service
Kubernetes services bridge your application pods to external traffic and other services within the cluster. It ensures stable access to the requested resource no matter which pod handles the request.
Kubernetes services are 3 types – ClusterIP, NodePort, and LoadBalancer.
apiVersion: v1 kind: Service metadata: name: <name of the service> namespace: <namespace> # Optional spec: selector: <key>: <value> # Labels to match in pods that are exposed by the service. ports: - port: <port number> # Port over which the service accepts traffic targetPort: <target port on pods> # Port on pods to forward traffic to protocol: TCP # Protocol (TCP or UDP) type: <service-type> # ClusterIP, NodePort, LoadBalancer
ClusterIP
This type of service is available within the Kubernetes cluster only. It is accessible by the other pods using a service IP.
apiVersion: v1 kind: Service metadata: name: my-clusterIP-service spec: selector: app: my-sample-app # Selects pods with the label "app: my-sample-app". ports: - port: 80 ## Accepts traffic on port 80 targetPort: 8080 ## Forwards traffic to port 8080 on the pods type: ClusterIP
NodePort
This type of service is exposed on each node’s IP with a specific port, accessible externally with the node IP and port.
apiVersion: v1 kind: Service metadata: name: my-nodeport-service spec: selector: app: my-sample-app # Selects pods with the label "app: my-sample-app". ports: - port: 80 # Accepts traffic on port 80 targetPort: 8080 # Forwards traffic to port 8080 on the pods nodePort: 30080 # Exposes the service on each node's port 30080 type: NodePort
LoadBalancer
This type of service is basically a load balancer. External load balancer automatically distributes traffic across pods, providing a single IP for external access.
apiVersion: v1 kind: Service metadata: name: my-loadbalancer-service spec: selector: app: my-sample-app # Selects pods with the label "app: my-sample-app" ports: - port: 80 # Accepts traffic on port 80 targetPort: 8080 # Forwards traffic to port 8080 on the pods type: LoadBalancer
ConfigMap
Kubernetes ConfigMap is an object that is used to store configuration-related data in key-value pairs. Using ConfigMap we can decouple environment-specific configuration from our container images, which makes our applications easily portable across environments.
apiVersion: v1 kind: ConfigMap metadata: name: my-sample-configmap data: # Key-value pairs for configuration data database_url: postgres://username:password@host:port/database api_key: your-api-key greeting: "Hello World!" # You can also include entire files: my-config-file.properties: | property1=value1 property2=value2
StatefulSet
StatefulSet is a Kubernetes object that works like a Kubernetes controller, and it manages the deployment and scaling of stateful applications.
apiVersion: apps/v1 kind: StatefulSet metadata: name: my-sample-statefulset spec: serviceName: my-sample-service # Name of the Headless Service replicas: 3 selector: matchLabels: app: my-sample-app ## Labels to identify pods managed by the StatefulSet template: metadata: labels: app: my-sample-app spec: containers: - name: my-sample-container image: my-sample-image:latest ports: - containerPort: 8080 volumeClaimTemplates: - metadata: name: my-sample-volume spec: accessModes: [ "ReadWriteOnce" ] storageClassName: my-sample-storage-class ## Use a specific storage class resources: requests: storage: 1Gi ## Request 1GB of storage per pod
Below are key points to be noted for the above manifest file –
- The StatefulSet will create three pods with unique names (my-sample-statefulset-0, my-sample-statefulset-1, my-sample-statefulset-2).
- A Persistent volume with 1GB of storage will be attached to each of the pods.
- Pods will be created, updated, and deleted in the order of their ordinal index (0, 1, 2).
HorizontalPodAutoscaler
In Kubernetes, a HorizontalPodAutoscaler (HPA) is an autoscaler that automatically adjusts the number of replicas in a deployment or stateful set based on observed metrics.
apiVersion: autoscaling/v1 kind: HorizontalPodAutoscaler metadata: name: sample-app-scaler spec: minReplicas: 2 maxReplicas: 5 targetCPUUtilizationPercentage: 50 scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: sample-deploy ## This name should match with the deployment name.
VerticalPodAutoscaler
VerticalPodAutoscaler is a Kubernetes object that helps in autoscaling the resources (CPU, memory) in each pod based on observed metrics. In this case, it focuses on increasing/decreasing resources in the existing pod instead of increasing/decreasing the number of pods.
apiVersion: autoscaling.k8s.io/v1 kind: VerticalPodAutoscaler metadata: name: sample-app-vpa spec: targetRef: apiVersion: "apps/v1" kind: Deployment name: sample-deploy ## This name should match the deployment name. updatePolicy: updateMode: "Auto" ### If we set "Auto" here, VPA will check the real-time resource utilization.
StorageClass
StorageClass is a Kubernetes object using which classes of storage can be described. A StorageClass in Kubernetes is like a blueprint for storage. It defines the type, quality of service (QoS), and provisioning details for persistent storage that can be requested by Pods in the Kubernetes cluster.
apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: my-sample-storage-class provisioner: kubernetes.io/aws-ebs # Replace with your provisioner. parameters: type: gp2 # EBS volume type reclaimPolicy: Retain # It preserves volumes on deletion. allowVolumeExpansion: true # It enables volume expansion.
PersistentVolume
PersistentVolume (PV) is a Kubernetes object using which a piece of pre-provisioned storage is made available for use by Pods in your cluster.
apiVersion: v1 kind: PersistentVolume metadata: name: my-sample-pv spec: capacity: storage: 1Gi ## Size of the volume accessModes: - ReadWriteOnce ## Access mode (how pods can access the volume) persistentVolumeReclaimPolicy: Retain ## Policy for volume reuse. storageClassName: my-sample-storage-class ## Optional: link to a StorageClass hostPath: ## Path on the host node where the volume is located. path: /mnt/data
PersistentVolumeClaim
PersistentVolumeClaim (PVC) is a Kubernetes object that is used to request storage by a pod.
apiVersion: v1 kind: PersistentVolumeClaim metadata: name: my-sample-pvc spec: storageClassName: my-sample-storage-class # Optional: reference the StorageClass. accessModes: - ReadWriteOnce resources: requests: storage: 1Gi # Request 1GB of storage
To give you an example of how pod requests for storage using PersistentVolumeClaim, below is one sample pod manifest file.
apiVersion: v1 kind: Pod metadata: name: my-sample-pod spec: containers: - name: my-sample-container image: my-sample-image volumeMounts: - name: my-sample-volume mountPath: /data volumes: - name: my-sample-volume persistentVolumeClaim: claimName: my-sample-pvc
Please note in the above pod manifest file, we have added the PersistentVolumeClaim (PVC) name.
Job
In Kubernetes, Job is an object which is a type of workload controller that defines a batch of non-recurring tasks to be executed to completion.
apiVersion: batch/v1beta1 kind: Job metadata: name: my-sample-job spec: template: spec: containers: - name: busybox image: busybox:latest command: ["sh", "-c", "echo Hello from Job! && sleep 10"] restartPolicy: OnFailure # It will retry failed tasks. parallelism: 2 # It will run two pods in parallel. backoffPolicy: type: Exponential # It will retry failed pods with increasing delay. backoffSeconds: 10 # It will initial delay for retries. maxDuration: 30 # It will maximum retry duration.
Thank You.
If you are interested in learning DevOps, please have a look at the below articles, which will help you greatly.
- Basics of automation using Ansible | Automate any task
- Automation of Java installation – using Ansible
- Automation of Tomcat installation – using Ansible
- 10 frequently used ansible modules with example
- Jenkins Pipeline as code – High level information
- Jenkins pipeline script to build Java application and push artifacts into repository
- Jenkins pipeline script to build & deploy application on web server
- What is End-to-End Monitoring of any web application, and Why do we need it?
- What is “Monitoring” in DevOps? Why do we need to Monitor App/DB servers, Transactions etc.?
- DevOps Engineer or Software Developer Engineer which is better for you?- Let’s discuss
- How To Be A Good DevOps Engineer?
- How to do git push, git pull, git add, git commit etc. with Bitbucket